一些编译cuda的笔记(更新中)
环境配置
CUDA支持离卡编译,因此CUDA Toolkit和其它各路编译套件完全可以装在没有N卡的机器上,然后完成所有编译工作。但是编译完的程序当然还是需要在有N卡的机器上才能运行
- Visual Studio: C/C++编译器
如果电脑原先没有安装VS,那只安装VS Build Tools就足够了:从微软官网获取Visual Studio 2026生成工具(页面下拉,在所有下载里面选择“用于Visual Studio的工具”就能找到。或者,如果需要兼容性,可以选择VS2022或者VS2019然后在安装的时候,选择“使用C++的桌面开发”。组件可以适当精简,比如截至当前的cuda版本(13.0),NVIDIA官方支持2019和2022
MSVC AddressSanitizer和vcpkg包管理器可以不需要。如下图所示:
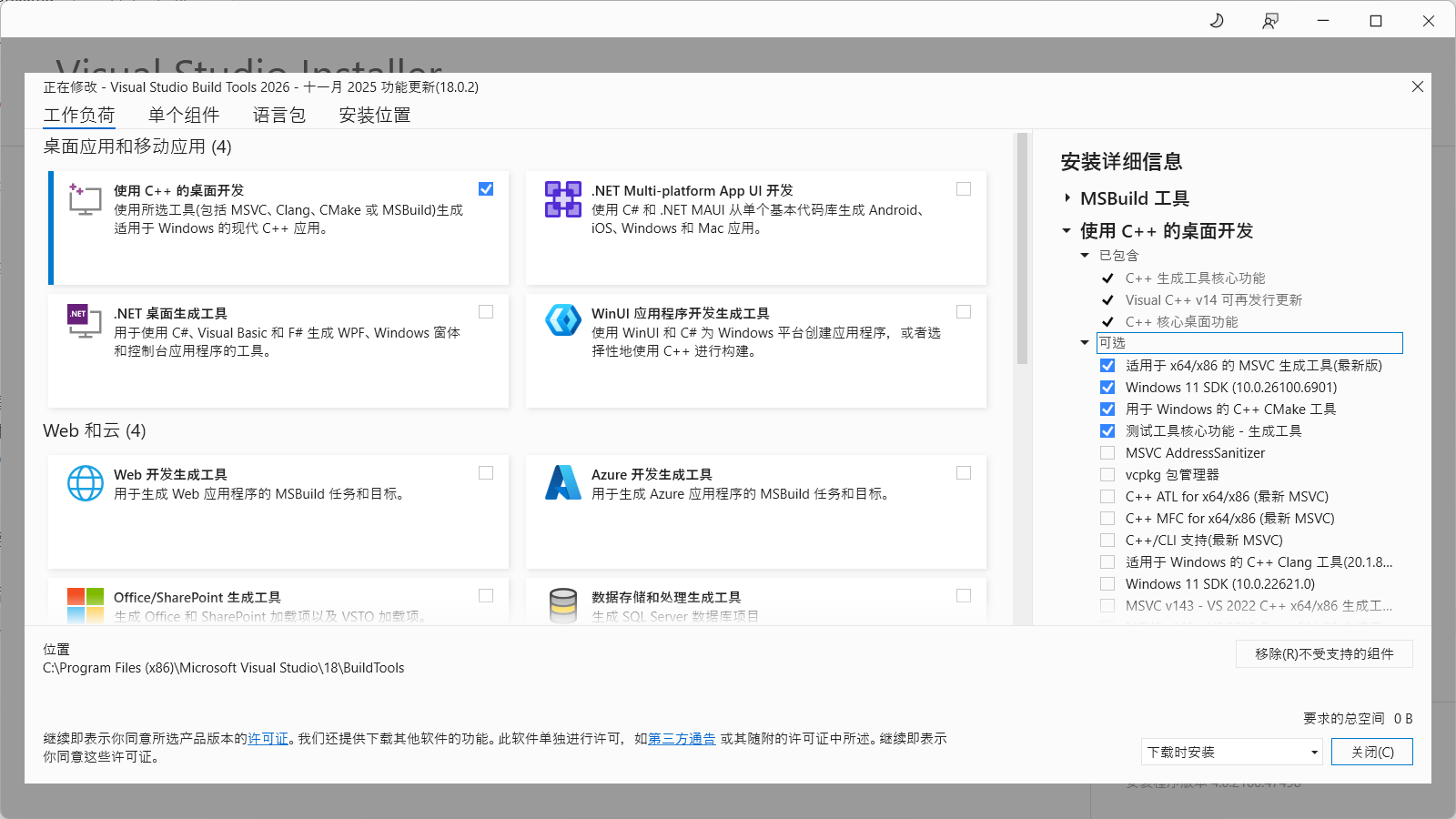
安装完成后,编译器默认并不会被添加到环境变量,也不建议直接把编译器添加到PATH。
在开始菜单中可以看到专用的工具项,从这里启动就可以进入相应的cmd和powershell:

为了简单快捷,可以自己在喜欢的位置创建一个空文件夹,里面编写一个setcl.bat内容如下(假设VS Build Tools安装到默认路径):然后把这个文件夹添加进环境变量1
2@echo off
"C:\Program Files (x86)\Microsoft Visual Studio\18\BuildTools\VC\Auxiliary\Build\vcvars64.bat"PATH,之后只要在任意位置运行setcl命令,就能等效于立即启动x64 Native Tools Command Prompt for VS如果想要测试,可以编译一个示例,看看是否正常工作。示例代码来自Microsoft官方文档一般都是在64位主机上编译目标为64位的程序,所以干脆直接启动这个,免得混淆。
如果希望在命令行快捷启动其它的,可以按照开始菜单的启动项右键→打开文件位置→右键快捷方式→属性查看对应的启动项到底是在执行什么指令,然后用类似的方式搓成脚本。▶Chello.c
1
2
3
4
5
6
7#include <stdio.h>
int main()
{
printf("Hello, World! This is a native C program compiled on the command line.\n");
return 0;
}1
2cl hello.c
hello.exe▶C++hello.cpp
1
2
3
4
5
6#include <iostream>
using namespace std;
int main()
{
cout << "Hello, world, from Microsoft C++!" << endl;
}1
2cl /EHsc hello.cpp
hello.exe - Cuda Toolkit: Cuda编译器
前往NVIDIA Cuda Toolkit官网下载,安装的时候自定义组件仅选择Runtime和Development两项即可:
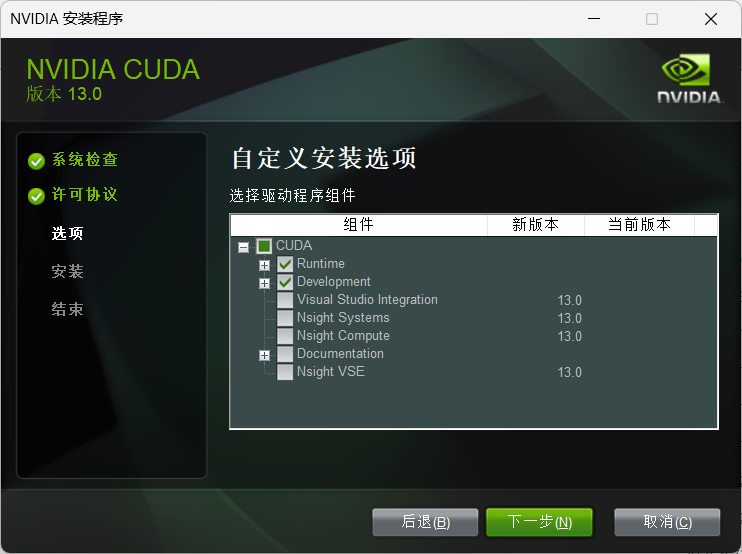 安装完成后,同样可以编译一个示例测试一下。注意虽然nvcc直接添加进PATH了,但是仍然需要
安装完成后,同样可以编译一个示例测试一下。注意虽然nvcc直接添加进PATH了,但是仍然需要截至cuda 13.0 update 2版本,nvcc尚未官方支持vs2026。如果使用vs2026,会提示编译器不受支持,需要在编译时添加参数
-allow-unsupported-compiler。可以使用环境变量把编译参数固定下来,NVCC_PREPEND_FLAGS将编译参数插入在其它参数的开头,NVCC_APPEND_FLAGS将编译参数追加在其它参数的末尾。cl.exe提供C/C++编译器,所以仍然需要确保VS环境处于激活状态。▶CUDAhello.cu
1
2
3
4
5
6
7
8
9
10
11
12
13
14#include <stdio.h>
__global__ void hello_from_gpu ()
{
printf("Hello from GPU! \n");
}
int main (void)
{
hello_from_gpu<<<4,4>>>();
cudaDeviceSynchronize();
return 0;
}编译后会输出16行”Hello from GPU!”
1
2nvcc hello.cu
hello.exe - cuDNN库:可能需要
前往NVIDIA cuDNN官网,下载安装即可,可以在自定义里面选择是需要cuda13的版本还是cuda12的版本。虽然写的是12.9,但是对cuda12全兼容,如果cuda用了12.8也可以放心使用。
- 其它可选工具
建议全局安装一个cmake和ninja,如果不安装也问题不大,pip里面也有这两个工具。
喜欢scoop的当然可以用scoop来安装。1
winget install Kitware.CMake Ninja-build.Ninja
编译记录
2026年3月8日:更新自编译推荐度,以满分5星为标准,但是实际上只能评出接近满分和接近0分两种极端……
xformers
推荐自编译指数:1.5星
理由:
- xformers当前版本已经适配了pytorch稳定abi,因此现在xformers不再需要与torch版本一对一绑定,最新的
xformers 0.0.35的依赖已经变成了torch>=2.10.0,因此意味着以后torch更新可以直接使用现有xformers,而无需在等待官方适配之前先自己编译一份顶上(直接用torch nightly都大概率没问题); - xformers官方开摆了:fa2和fa3都直接用torch的,xformers现在这个轮子大小剩不了多少了;不过xformers底层的mem eff优化还是更省显存,xformers和sdp现在的关系是,sdp更快但是更费显存,看需求用,但是自编译也没多少模块了;
不过这也意味着,现在编译xformers速度可以相当快; - 对于新显卡xformers官方更是摆:官方不会正式支持Blackwell了
所以xformers现在没有正常内置cutlass-Blackwell的bug估计也很难等到修复了;
如果Blackwell GPU使用xformers遇到类似这种报错:有一个临时的修复方案,无需编译。1
NotImplementedError: No operator found for `memory_efficient_attention_forward` with inputs
前往python环境里面的xformers目录,通常可以在环境目录底下的Lib/site-packages里面找到xformers文件夹。修改里面的ops/fmha/cutlass.py,定位到170行左右:这样就能正确启用1
2
3
4
5
6
7
8
9OPERATOR = (
get_operator("aten", "_efficient_attention_forward")
if is_pt_cutlass_compatible()
else None
)
- CUDA_MAXIMUM_COMPUTE_CAPABILITY = (9, 0)
+ CUDA_MAXIMUM_COMPUTE_CAPABILITY = (12, 1)
SUPPORTED_DEVICES: Set[str] = {"cuda"}
SUPPORTED_DTYPES: Set[torch.dtype] = {torch.float, torch.half, torch.bfloat16}cutlass-pt模块,由于这个cutlass是pytorch提供,因此无需担心对新卡的适配不好。 - 对于未来更新的显卡(Rubin及以后),按照xformers现在这种摆烂方式,有可能直接就不可用了,到那个时候想自己尝试尝试编译也行,但是大概率意义不大。
由于flash-attn2目前最后一个能在Windows上编译的版本是2.7.4,从2.8开始截止当前版本2.8.3在Windows上均会编译失败,因此xformers内置的flash-attn2在升级到2.8之后也无法在Windows上通过编译。
xformers最后一个绑定flash-attn2.7.4的版本是0.0.30,已知可以稳定配合pytorch2.7,因此如果官方包遇到兼容性问题(尤其是Blackwell GPU),自己编译一版0.0.30去配合torch2.7.1+cu128应该是个不错的选择。
从0.0.31开始,Windows上无法编译出含flash-attn2的xformers轮子。不是很建议尝试在旧xformers上强行为新版torch编译,适配大概率会比较差。
或者,编译一版不含flash attention的xformers,只使用mem eff优化也存在可行性,并且这样的话,编译所需时间会极大幅度缩短,内存压力也会极大幅度减小。即使没有fa2,单纯的xformers经测试也会比torch sdp更省显存。
- 获取源码:从github获取最新源码,或者从pypi获取指定版本的源码压缩包。 从github获取的时候要clone submodule:
从这个commit开始,xformers主动提前适配了torch2.10nightly版本的API,弃用了对torch2.9版本的支持。
因此,如果需要为torch2.9编译,那就不能直接连同submodules一起clone,而需要使用git checkout或者git reset --hard先切回旧版本:1
2
3git clone https://github.com/facebookresearch/xformers.git
cd xformers
git reset --hard 513e7a43aba20b22b6b52a32a5d17896ff0e2bd7然后再执行下文的
git submodule update --init --recursive或者如果1
git clone https://github.com/facebookresearch/xformers.git --recurse-submodulesclone的时候忘记,那么进入xformers源码根目录下执行:对于pypi获取的压缩包,解压并且删除里面的1
git submodule update --init --recursivexformers.egg-info文件夹。git在默认设置下使用Windows的旧版API,其不支持长路径,需要通过git config开启长路径支持:
1
git config --global core.longpaths true或者,如果有洁癖不想动全局配置,那就
clone的时候不要--recursive-submodules,然后为仓库单独开启长路径之后再执行git submodule update。
如果没有开启长路径,然后clone期间出现Filename is too long报错,不要抱有任何侥幸心理,把源码文件夹整个删除,开启长路径支持之后再重新整个拉取,这是确保文件夹里的源码和预期一致的最稳妥的方法。 - 准备环境:建议使用venv虚拟环境,然后
pip安装计划和xformers搭配的torch以及xformers的依赖numpy。如果前面没有安装全局的ninja,这里就一起安装一个,否则没有并行编译会纯纯龟速。
与此同时,如果有用uv的习惯,那后面启动编译直接用uv就好(也可以pip install uv);或者用更官方一点的方式,pip install build setuptools wheel。 - 微调
setup.py(可选):- 首先咱不喜欢xformers在版本号里面记录编译日期;用git commit hash就足以指示编译的准确版本。因此删除开头的
import datetime;然后定位到get_local_version_suffix()函数,修改:1
2
3
4
5
6
7
8
9
10def get_local_version_suffix() -> str:
if not (Path(__file__).parent / ".git").is_dir():
# Most likely installing from a source distribution
return ""
- date_suffix = datetime.datetime.now().strftime("%Y%m%d")
git_hash = subprocess.check_output(
["git", "rev-parse", "--short", "HEAD"], cwd=Path(__file__).parent
).decode("ascii")[:-1]
- return f"+{git_hash}.d{date_suffix}"
+ return f"+{git_hash}" - 然后,由于flash attention v3仅支持A100,H100等计算卡,不支持Geforce游戏卡;计算卡要用也是在Linux上用,而Linux上既有满血的torch flash attn2也有xformers官方的满血fa3,因此Linux上自编译xformers的必要性也小些。所以修改源码直接屏蔽fa3编译:
1
2
3
4def get_flash_attention3_nvcc_archs_flags(cuda_version: int):
+ return []
if os.getenv("XFORMERS_DISABLE_FLASH_ATTN", "0") != "0":
return [] - 下调nvcc threads:由于nvcc编译flash attn部分极其费内存,把nvcc threads调小降低内存压力:
1
2
3
4
5
6
7
8if cuda_version >= 1102:
nvcc_flags += [
"--threads",
- "4",
+ "1",
"--ptxas-options=-v",
]
if sys.platform == "win32":
- 首先咱不喜欢xformers在版本号里面记录编译日期;用git commit hash就足以指示编译的准确版本。因此删除开头的
- 设置环境变量:
XFORMERS_DISABLE_FLASH_ATTN根据编译需求设置:
设为0:开启xformers内置的flash-attn,包括fa2和fa3;此时这个选项仅是开启fa的必要条件,开启后上文屏蔽fa3的设置依旧有效;在高版本下编译fa2极大可能失败。
设为1:直接禁用fa2和fa3,只编译最基础的xformers mem eff优化。
对于旧版本xformers0.0.30,这个环境变量默认会取0;当前版本0.0.33已经改为默认取1XFORMERS_PT_FLASH_ATTN设置为0
Windows下pytorch根本没有编译flash attn组件,此选项让xformers编译自己打包的的flash attn,如果xformers版本高于0.0.30则不要开启,大概率会导致编译失败。
如果上一个环境变量已经设为1禁用了flash attn,那么这个环境变量会被无视。TORCH_CUDA_ARCH_LIST按以下规则设置:比较重要
首先根据NVIDIA文档确定GPU与cuda arch版本号的关系。然后确定编译目标:不在此表上的GPU已经不在cuda13的支持范围;如果需要在cuda12或者旧版本上为老显卡编译,参看NVIDIA文档
- 如果只想自用,那就只填自己的(例如RTX50系填
12.0); - 如果想自己选择几代不同的架构,就用分号分隔(例如如果想同时支持RTX40和50系,填
8.9;12.0); - 如果想搞成类似官方的泛用包,这里(在huggingface上)记录了一些xformers官方用过的环境变量可以照抄;
- 如果不设置,xformers的默认行为会有所差异:flash attn2模块里面设定了一个默认列表,会根据cuda版本的不同启用不同的默认列表,然后将flash attn2的模块为列表中的所有架构编译;flash attn3模块则是检测本机是否是8.0(A100等)或者9.0(H100等),如果是,就针对本机架构编译,否就直接不编译。其它模块不确定,但是应该是针对本机架构编译。为了确保精准控制自己的需求,建议设置;
- 如果手动设置的列表里面不含8.0和9.0,那么fa3模块会自动不启用,因此上文的手动屏蔽此时不再需要。
- 如果只想自用,那就只填自己的(例如RTX50系填
XFORMERS_PT_CUTLASS_ATTN可选设置,控制是否借用torch的cutlass的开关,设置为0禁用,默认启用。这个影响不大,不设保持默认行为也可,稍微节约一点点编译时间;设为0是模拟旧版本的行为MAX_JOBS控制ninja的并行数:特别需要注意,因为xformers编译过程中,部分环节特别特别吃内存;而ninja的默认行为是把并行数直接开到CPU线程数+2,对于常规的消费级电脑,如果编译fa2,这个设置几乎一定会爆内存。
作为参考,在fa2能通过编译的时候,咱自己的个人配置MAX_JOBS=2能不爆16GB内存,开到3就会开始触发大量虚拟内存交换,甚至会导致中断退出。根据自己的内存调整即可。咱测试的时候没动过nvcc threads,如果按照上文把nvcc threads降低,那有可能这个数值可以开高点,这样至少纯C++无CUDA的部分可以编译快点。
如果选择不编译flash attention部分,在前面把nvcc threads减到1的前提下16G内存可以直接开8,编译很快就会完成。NVCC_FLAGS:对于vs2026如果上文没有配置-allow-unsupported-compiler,xformers的编译程序接受这个环境变量作为追加编译参数,设置在这也是可以的。
- 启动编译: 导航到xformers源码的根路径,如果使用uv,就执行
可以使用
chcp 65001把输出切换到UTF-8编码,这样msvc编译器输出的中文不会乱码,可以更清晰地查看日志输出。如果使用build,在以下两种命令选一种;build的默认日志可能输出没那么多,如果缺少安全感就加个1
uv build . --no-build-isolation-v多看看日志刷屏注意上述命令的默认行为是,先把源码打包成源码包(sdist),就像pip的源码压缩包那样;然后对源码包执行编译。1
2python -m build . -n
pyproject-build . -n
如果想直接只编译whl,那就额外添加--wheel参数。
经过漫长的编译之后,产物会出现在dist文件夹,妥善保存。按照python现行规范,直接用
python执行setup.py的行为都应当被替代:旧命令 新命令 python setup.py installpip install .python setup.py developpip install -e .python setup.py sdist,python setup.py build以及python setup.py bdist_wheelpython -m build其中后者会默认在TEMP目录下创建隔离的编译环境,视情况添加类似
--no-build-isolation的参数改变这个行为。
上游flash-attn可能要注意的
推荐自编译指数:2
flash-attn的问题是官方自己没搞二进制轮子;但是各种民间轮子已经满天飞,如果有适配的轮子肯定直接用就好,如果没有再来考虑编译。
额外提一下编译flash-attn2可能需要注意的事项,和编译xformers无关,编译xformers不用看本节。
由于咱的设备不支持flash attention2,环境变量的注意事项完全来自于手撕源码setup.py。
- flash-attn同样支持且建议使用
ninja并行编译加速,如果想使用pip install ninja的话注意build isolation问题。 NVCC_THREADS
nvcc的线程数,默认为4,当编译内存不够时可以先考虑压低这个数值,从而尽量减少对编译纯C/C++部分的速度影响(纯C/C++编译通常吃不了多少内存)FLASH_ATTN_CUDA_ARCHS
flash-attn使用这个环境变量来控制编译的目标GPU架构,默认值是80;90;100;110;120(也就是全编译)。这样非常浪费时间,因此强烈建议设置该环境变量,仅编译自己的GPU架构。另外该值只接受0结尾,因此对于30系(sm86)和40系(sm89)也应该使用80MAX_JOBS和xformers部分相同。
llama-cpp-python
推荐自编译指数:5
llama.cpp是非常推荐自行编译的。llama.cpp的源码里面有大量检测本机硬件针对优化的流程,自编译的轮子的性能会明显强于一些预编译的通用轮子。
至少在咱这里,用预编译轮子,在cuda版本确认正确的情况下,GPU根本起不来,速度和CPU完全一样;自编译就能正确调用上。
对于AMD的zen4以上用户,llama.cpp会检测CPU支持的指令集,并开启AVX512优化;由于llama.cpp的推理是CPU和GPU都有参与工作,因此开启AVX512也能得到收益。
再者,llama-cpp-python并不检测pytorch内置的cuda运行库,因此即使使用预编译包,也需要从cuda toolkit至少安装cuda runtime,那cuda toolkit装都装了不如自己编译一下得了。
最后,项目不大,只要正确配置好并行加速,编译时间并不会很长。
llama-cpp-python的官方文档也是优先推荐自行编译。
onnxruntime-gpu
推荐自编译指数:0
项目过大,编译时间过长,非常非常折磨。
咱会想到自编译,纯粹是因为torch的cu130到来之后,咱想冲版本,但是onnxruntime-gpu的cu13适配来的实在太慢,所以没忍住自己搞了一版;
在cu14到来之前,没有任何理由再开一次编译,这里仅做一下记录。
现在pypi提供的onnxruntime-gpu仍为cu12版, 如需cu13,安装方式:
1 | |
- 获取源码:
1 | |
- 根据目标python版本准备好一个对应python版本的环境(虚拟环境venv或者conda什么的皆可),确保这个环境处于激活状态。也就是说,执行
python命令可以正确启用想要版本的python。 - 确保已经安装好cuda和cudnn;其中Windows下的cudnn不能使用安装版,因为安装版的目录结构会是这样:
安装版的在▶tree
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43NVIDIA
└── CUDNN
└── v9.20
├── bin
│ └── 13.2
│ └── x64
│ ├── cudnn64_9.dll
│ ├── cudnn_adv64_9.dll
│ ├── cudnn_cnn64_9.dll
│ ├── cudnn_engines_precompiled64_9.dll
│ ├── cudnn_engines_runtime_compiled64_9.dll
│ ├── cudnn_graph64_9.dll
│ ├── cudnn_heuristic64_9.dll
│ └── cudnn_ops64_9.dll
├── include
│ └── 13.2
│ ├── cudnn.h
│ ├── cudnn_adv.h
│ ├── cudnn_backend.h
│ ├── cudnn_cnn.h
│ ├── cudnn_graph.h
│ ├── cudnn_ops.h
│ └── cudnn_version.h
├── lib
│ └── 13.2
│ └── x64
│ ├── cudnn.lib
│ ├── cudnn64_9.lib
│ ├── cudnn_adv.lib
│ ├── cudnn_adv64_9.lib
│ ├── cudnn_cnn.lib
│ ├── cudnn_cnn64_9.lib
│ ├── cudnn_engines_precompiled.lib
│ ├── cudnn_engines_precompiled64_9.lib
│ ├── cudnn_engines_runtime_compiled.lib
│ ├── cudnn_engines_runtime_compiled64_9.lib
│ ├── cudnn_graph.lib
│ ├── cudnn_graph64_9.lib
│ ├── cudnn_heuristic.lib
│ ├── cudnn_heuristic64_9.lib
│ ├── cudnn_ops.lib
│ └── cudnn_ops64_9.lib
└── LICENSEbin,lib等目录下都至少套了一层CUDA版本的路径,有的在底下还套了一层x64,onnxruntime的编译不能识别这样的路径。
因此需要用软链接的方式,或者用cudnn的tarball包,组织成这样的结构:同样的,对于.deb系的Linux,由于会分布在1
2
3
4
5
6
7
8
9
10cudnn-windows-x86_64-9.20.0.48_cuda13-archive
├── bin
│ └── x64
│ └── ...
├── include
│ └── ...
├── lib
│ └── x64
│ └── ...
└── LICENSE/usr/lib/x86_64-linux-gnu和/usr/include/x86_64-linux-gnu也会变成非标路径,因此如果遇到识别问题,也应该考虑改用tarball包重新组织路径结构。 - 根据平台,Windows使用
build.bat启动,Linux使用build.sh启动,且需要的所有前置环境和编译参数如下:cmake: 核心,项目是cmake项目当然必须需要cmake启动ninja: 强烈建议使用,对于这种重型项目,ninja的调度优势无论是对比msbuild还是对比GNU make都强了不知道多少;且windows下用ninja调度cl能更好的配合ccache加速,msbuild测试几乎无法命中ccache;
另外强调一下,如果是默认的msbuild,那么msbuild自己就能找到编译器;但是Ninja并不能自己找到cl.exe,因此ninja需要在vs command prompt下使用。为了保险,建议直接使用x64 native command promptccache: 同样强烈建议使用。onnxruntime项目本身是大型的C++/CUDA混合项目,ccache对两种的编译都能起到缓存作用;而且必须提及的一点是,CUDA部分会有一些模块的编译相当吃内存,但是为了这个模块直接限制总并行数也很亏;所以高效的选择肯定是,先火力全开,到了吃内存的部分,Ctrl+C干掉,然后调整并行数继续开。编译进度万一在重开的时候丢失了(Windows上概率很大)就是ccache缓存垫回来的时候了。- 启用以下编译参数,由于项目过于重型,因此编译的目标是:只编译最基础的包含CUDA/cudnn的模块,不编译TensorRT和NCCL(反正一般用不上),不编译其它语言,并且跳过所有测试,关闭PGO和LTO(太耗时):
--config Release--compile_no_warning_as_error--use_cache本项启用ccache--cmake_generator Ninja--skip_tests --skip_onnx_tests --skip_winml_tests --skip_nodejs_tests保险起见,全加--build_wheel核心,编译python wheel--parallel 0控制并行编译数,0的时候会取CPU最大线程数,nvcc爆内存了需要适当调一个比较小的正数--nvcc_threads 1nvcc的线程数,开1就好,这个体感收益似乎并不高?而且nvcc阶段的模块都是内存杀手,压制一下挺好--use_cuda启用cuda编译--cuda_version CUDA_VERSION --cuda_home CUDA_HOME这两个可以不用指定,cuda版本会自动检测,然后只要nvcc在PATH里面,就不需要手动指定路径;--cudnn_home CUDNN_HOME指定cudnn路径,如前文所言,需要确保路径如下:1
2
3
4
5
6
7CUDNN_HOME
├── bin
│ └── ...
├── include
│ └── ...
└── lib
└── ...
--cmake_extra_defines杂项,用来额外指定附加给cmake的选项,包含:
--cmake_extra_defines CMAKE_CUDA_ARCHITECTURES=75;86;89;120指定编译的目标CUDA架构,这个列表包含了20~50四代GeForce游戏卡,可以自己根据需求调整,节省时间只给自己的GPU编译也是可以的
--cmake_extra_defines onnxruntime_BUILD_UNIT_TESTS=OFF --cmake_extra_defines onnxruntime_BUILD_CSHARP_TESTS=OFF --cmake_extra_defines onnxruntime_BUILD_JAVA_TESTS=OFF把无关的测试禁用的更彻底一点,求稳妥,反正不会负负得正
完成之后,保存.whl文件,上传,然后这辈子不会再想编译第二次。